Apple, Google and Amazon are currently locked in an epic quest over the following multi-trillion dollar question: which company will be the first to maintain 99% accuracy for speech recognition from Natural Language Processing (NLP) in any and every scenario and context, for every language, dialect and slang?

Beyond just accurate intent and entity matching, there is another race in speech recognition — the race to organize and categorize audio dark metadata.
There are rarely discussed consequences of audio dark metadata for the privacy of 3rd parties who haven’t agreed to the Terms of Service of the company providing the audio processing — the un-agreed person standing on the train talking near a person dictating into a Google Assistant-powered app, or the co-worker talking about business as someone nearby asks Siri for directions to an after-work dinner, and many other potential scenarios.
There is a huge value for a business to acquiring and analyze dark audio metadata, and it’s important for the public and governing bodies to understand their value.
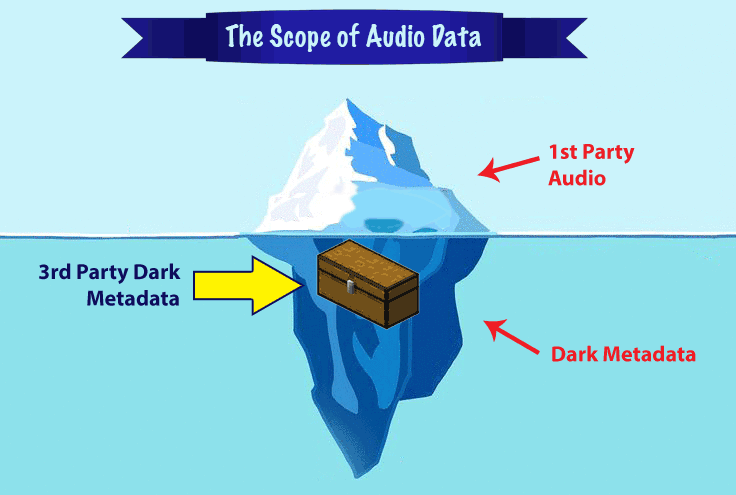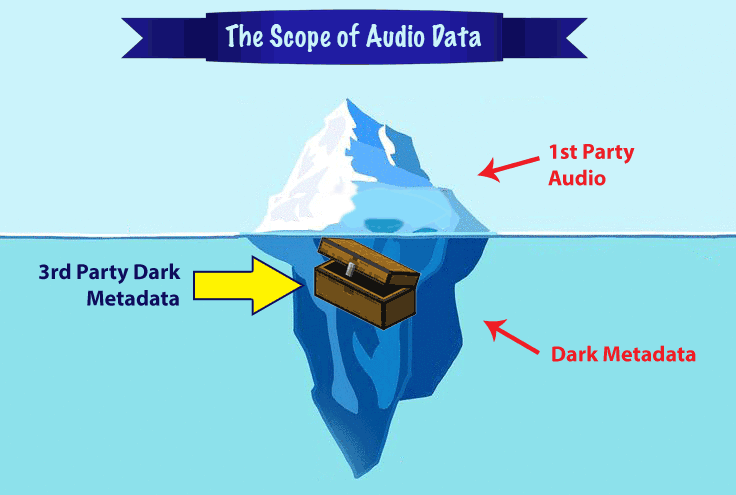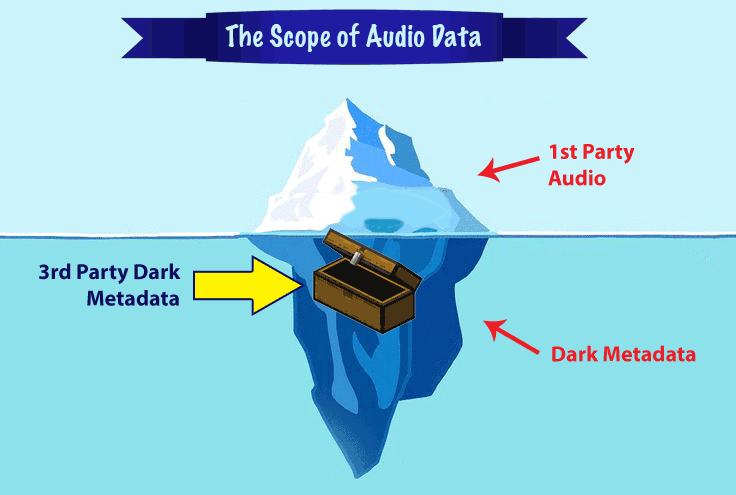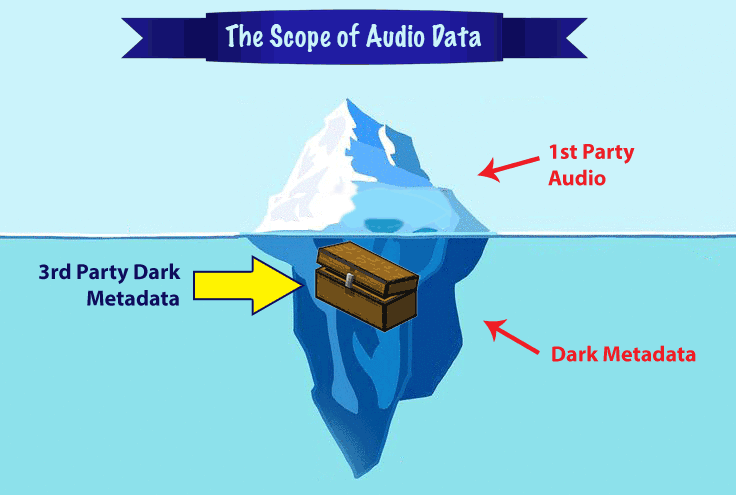
The winner of the speech recognition race will be the company that not only perfects their segmented NLP models, but also the one that does it under the legal, ethical and social norms required in the marketplace.
Apple appears to have a dominant position with their rarely-reported-on Hardware Abstraction Layer (“HAL”) architecture which attempts to process and provide some layer of anonymization directly on their devices before the data is stored. In contrast, Google, Amazon Microsoft and other companies appear to currently skip the on-device anonymizing step. Instead, their public statements and developer documents indicate that their audio Natural Language Processing (“NLP”) tools send all recorded audio to their servers, store it, and then don’t take additional steps to remove private 3rd party audio.
Indeed on Google, Amazon and Microsoft’s websites explaining their speech to text software, they make no mention of third party privacy rights or 3rd party audio dark metadata protection at all. Whether these companies have some work around for filtering and protecting third party metadata once on their server, remains to be seen.
What is abundantly clear, however, is that on May 25, 2018, the EU’s General Data Protection Regulation (GDPR) becomes effective, and creates a whole potential universe of additional liability with regard to the collection of third party audio dark metadata. Though most in the tech world have focused on first party data retention policies (terms of use, individual user privacy rights, enforceability of privacy agreements), protecting third party audio dark metadata — that is, data collected and recorded from people and things who are not the first party users of the speech device — marks the new frontier in privacy. With new regulations and privacy concerns growing daily, the ultimate winner of the speech recognition race will not only be the one who makes it to 99% recognition the fastest, but the company who successfully does this while also protecting the metadata of first and third party users.
Time is of the essence, due to GDPR going into effect on May 25th, 2018, and if a company doesn’t comply, the EU’s GDPR clearly states, “those organizations in non-compliance may face heavy fines.” The formula to determine GDPR fines could cost American businesses potentially hundreds of millions or billions of dollars, and as of publishing this article, there will be less than 3 weeks before the law goes into full effect.
If 3rd party audio dark metadata rights are included under GDPR, many companies need to make significant changes to their speech recognition NLP systems in a short period of time.
The Audio NLP Race for Enterprise Deployment + Audio Dark Metadata Collection and Filtering
Apple, Google, Amazon and dozens of other companies are in a race to perfect their Audio Natural Language Processing (NLP) systems and deploy it for enterprise clients and the public at-large.
Both Google and Amazon are moving forward with nearly identical strategies to create open audio NLP API’s so that 3rd party developers integrate their hardware with Google or Amazon NLP API’s — a strategy to win the race through enterprise deployments, which is the classic enterprise growth strategy. These integrations use the microphones in devices that record anything and everything and pass all of that audio data into Google and Amazon servers — scooping up all 3rd party audio dark metadata without any attempt to filter on-device.
Apple is approaching audio NLP radically different, with a focus on their on-device audio dark metadata collection and parsing to potentially protect user privacy, through their aptly-named “Hardware Abstraction Layer (HAL)” on all devices with Siri.

Apple modeled their on-device processing on some similar techniques that industrial NLP systems with limited-dictionary speaker-dependent processing have used. This is the type of industrial tech that powers voice activated bar code readers someone could use while working on a dock in Baltimore that has 50–60 core commands that are trained by each person. Apple is working under the same concept but just with one attempting to do it for every word in every language. Easy!
What is Dark Metadata and Why Does it Matter? The Hidden, Unstructured Data Needing to be Organized Before a Value Can be Defined

Dark metadata is a machine learning (ML) concept that is slightly hard to understand — basically it’s the concept of a firehose of unique and outwardly indecipherable data and then finding a way to organize that data so that the output has a new and distinct value.
Consider the following analogy: you want to come up with a way to identify every car in need of an oil change. But the only information you have is that you’re standing on a freeway overpass, trying to look at the make and model of every car that whizzes by you. For one person, that data collection and analysis would be impossible, but with the right visual and audio sensors and with enough training data and supplemental user data, the combination of the make, model, time, exhaust, speed, and temperature of every passing vehicle could create a business automation that would allow a business to advertise discount coupons for an oil change at the perfect time. Magic!
So, what does dark metadata have to do with the race for 99% speech recognition? Well, just about everything. It’s essentially the key that will unlock that final piece of the speech recognition puzzle, and Apple, Google and Amazon (and many other companies) know it.
For Apple’s part, it would at least outwardly appear they are focusing on identifying audio dark metadata and likely are trying to remove 3rd party metadata or anonymize it as background noise, but Google and Amazon have prominent sales and development resources stating that they store their audio Natural Language Processing (NLP) API data on servers prior to any analysis, making it literally impossible to remove 3rd party audio dark metadata prior to storage.
Google and Amazon (and other similar companies) aren’t hiding that they store all audio data before analysis, but they haven’t explained how they prove they are deleting 3rd party audio dark metadata that has been acquired outside their Terms of Service. All companies involved collecting 3rd party audio dark metadata should provide more details to the public, and everyone should likely figure out their own policies before GDPR goes into effect on May 25th, 2018.

Apple’s 2015 Acquisition of Perceptio Paved the Way for Device-Centric AI with Local Device Processing to Strengthen User Privacy
A largely under-the-radar AI acquisition from Apple came in 2015 when they purchased Perceptio, as reported by MacRumors who quoted the original Bloomberg piece:
Perceptio’s goals were to develop techniques to run AI image-classification systems on smartphones, without having to draw from large external repositories of data. That fits Apple’s strategy of trying to minimize its usage of customer data and do as much processing as possible on the device.
Over 3 years ago, Apple was already laying the groundwork for a privacy-centric NLP AI, and these steps to double-down on audio dark metadata with on-device processing have opened up untold strategic doors.
One way to think about the local processing of 3rd party audio dark metadata is through a simple scenario — imagine 20 people are sitting on a train and 12 people have iPhones and 2 of those people are asking Siri a question — 8 people total are talking. Siri could identify the 2 “primary user” speakers who have agreed to the Apple Terms of Service and start to identify all the background noises as “private 3rd party audio dark metadata” — everything from the known-train-whistle-sound (limited privacy concerns) to the knew and dynamic conversations of other people on the train (significant privacy concerns). In order for the privacy of the six-other people talking who aren’t using Siri and potentially not even Apple customers to be respected and not have their words and conversations documented, Apple’s 3rd-party audio dark metadata processing would be identifying that in real-time, and anonymizing any of the 3rd party audio dark metadata and then passing only the 1st-party audio metadata into Apple servers for user-identified storage and analysis. It’s possible that 3rd party user audio could be completely deleted if algorithms could identify words that would compromise another non-Apple user’s privacy.
Apple still needs to clarify publicly how they manage 3rd party audio dark metadata — and although they may be architected with Siri + HAL in a way that appears to more strongly support user privacy, they still need to proactively communicate to the public what they’re doing.

If audio streams aren’t being locally processed so the device can identify 3rd-party audio dark metadata before transmission to an off-site server, then that work needs to occur on-server after remote processing. If a company doesn’t filter 3rd party audio on-device, then, currently, the public at large has to trust companies to delete or anonymize/pseudonymize the 3rd-party audio dark metadata once they have it on their servers.
For both Google and Amazon, they provide free and extremely cheap NLP API services — and as the saying goes — if something is free, you’re the product.
The benefits for Amazon and Google to provide free and cheap speech to text processing services are greatly over-compensated by their collection of users’ 1st party metadata and 3rd party audio dark metadata. The same goes for Apple and any company working in this space — the public needs these services to develop new technology, but the 3rd party audio dark metadata needs to be acknowledged and protected — and policies to protect this data need to be communicated publicly.
Apple’s Spring 2017 Acquisition of Lattice Data, Dark Metadata Experts Who Created Stanford’s Open Source Deep Dive, Vital to Hal
As reported by Apple Insider after the May 2017 acquisition of Lattice Data, the goal of using dark metadata to train distant supervision machine learning is rooted in saving time and pushing speed and scale of deployment — with the initial privacy implications being somewhat ignored:
The company contrasts its approach to traditional machine learning, explaining “we do not require laborious manual annotations. Rather, we take advantage of domain knowledge and existing structured data to bootstrap learning via distant supervision. We solve data problems with data.”
The firm also emphasizes the “machine scale” of its platform in being able to “push the envelope on machine learning speed and scale,” resulting in “systems and applications that involve billions of webpages, thousands of machines, and terabytes of data” at what it describes as “human-level quality.”
As Apple has planned their HAL/SIRI speech to text privacy architecture for years, both Amazon and Google have been focusing on open speech to text networks and growing their data ingestion through enterprise deployments and the public-at-large. Only time will tell which strategy was correct.
Amazon’s Audio NLP Market Leadership — 3rd Party Audio Dark Metadata Stored via “Amazon Comprehend Voice of Customer Analytics”
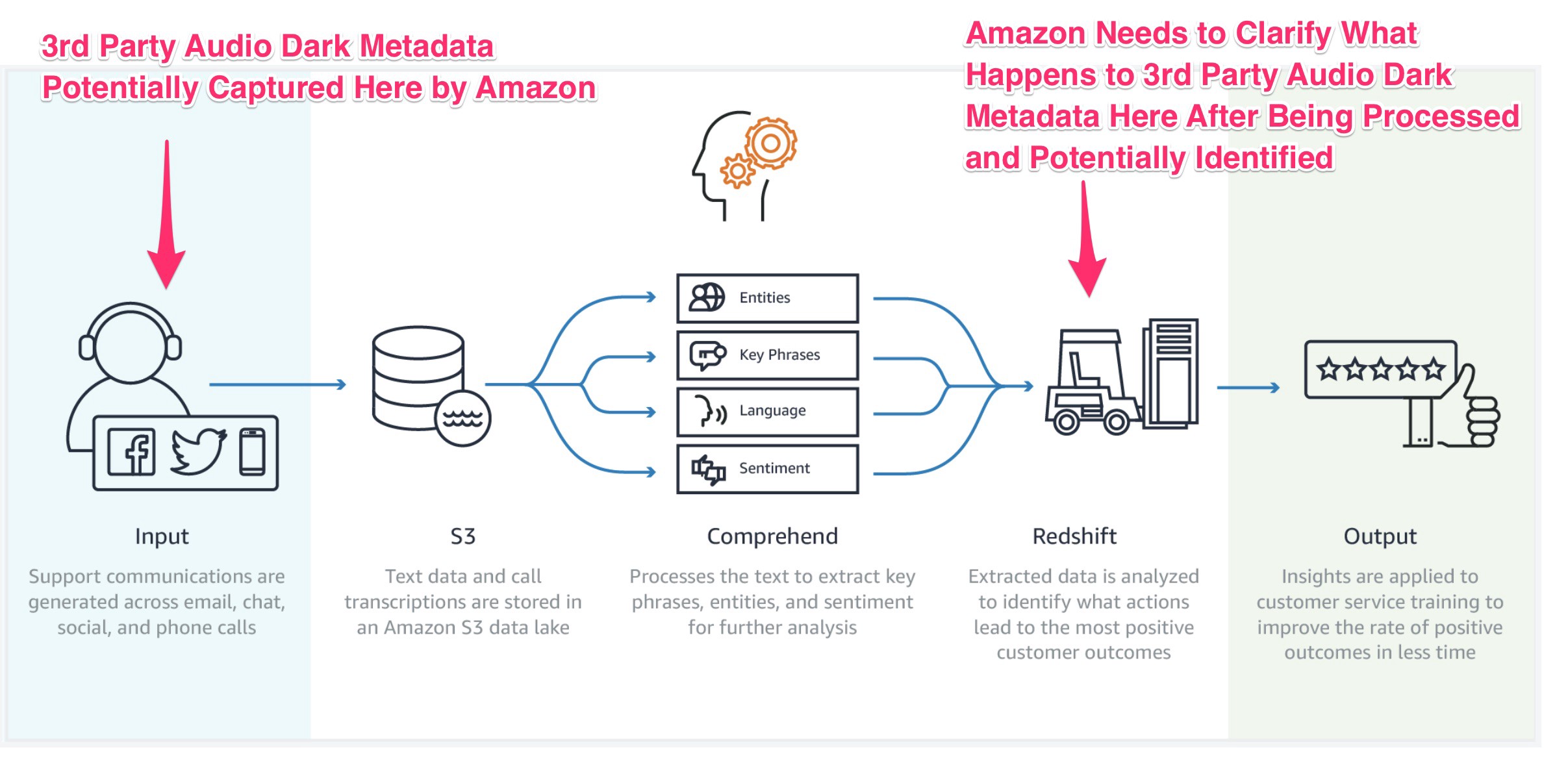
Amazon built what they call “Amazon Comprehend — Voice of Customer Analytics” — their Natural Language Processing (NLP) software available for developers working with audio to text.
Here’s the chart that Amazon has on their developers portal showing how audio data is stored before the data is parsed or processed. This proves that any app developers 3rd party audio dark metadata from non-agreed-TOS-parties would be transferred and stored by Amazon. The only thing not clarified here is if Amazon removes or anonymizes any data in the processing stage or at any time period afterwards.
Google has Extremely Strong Speech to Text NLP Developer Tools, No Mention of 3rd Party Privacy from Audio Dark Metadata After Storage
Google is a dominant force in AI, particularly with their Google Cloud Speech to Text developer tools. They have a global babel-fish API that can ingest audio in 120 languages — and has a variety of other labeling features:
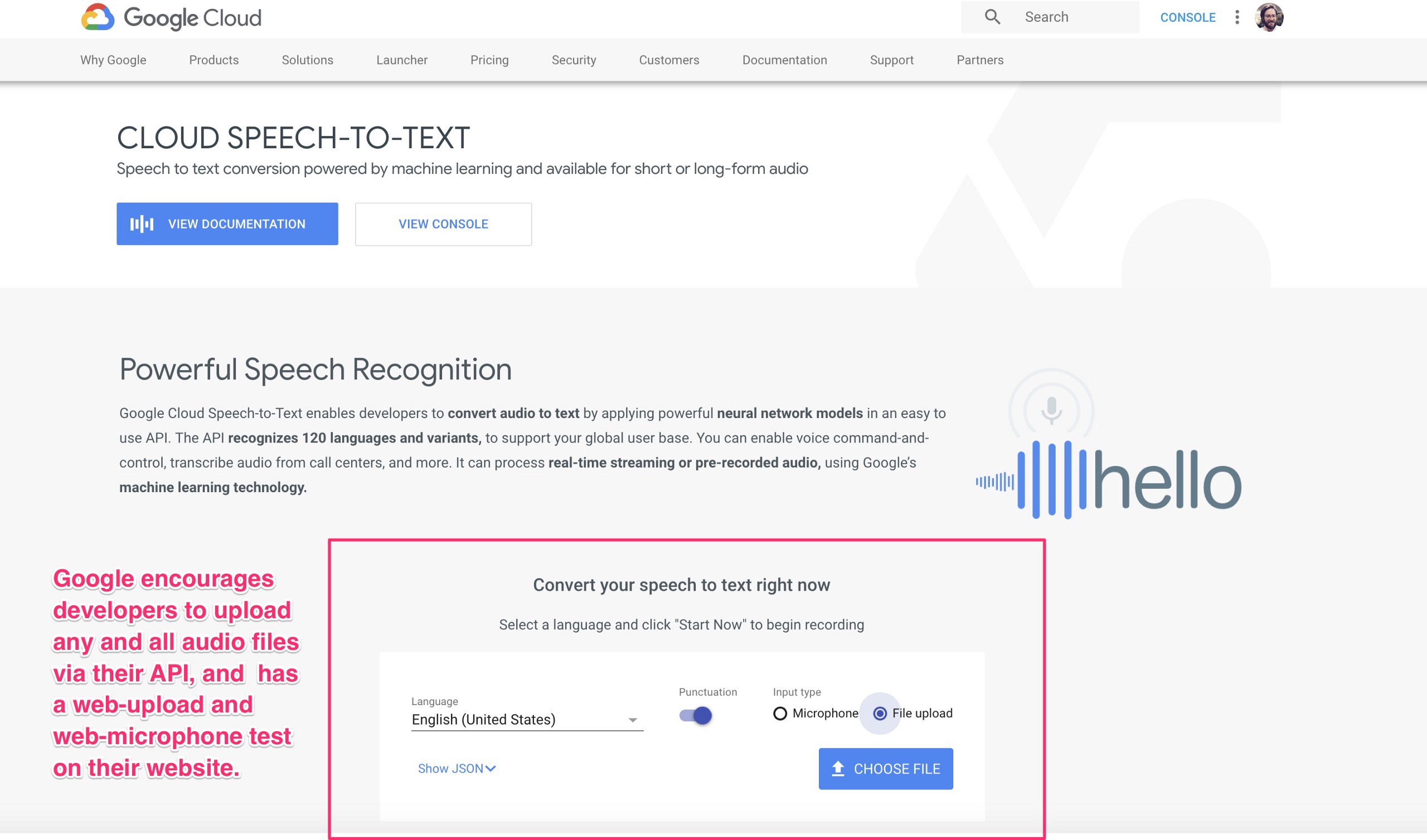
Google Cloud Speech-to-Text enables developers to convert audio to text by applying powerful neural network models in an easy to use API. The API recognizes 120 languages and variants, to support your global user base. You can enable voice command-and-control, transcribe audio from call centers, and more. It can process real-time streaming or pre-recorded audio, using Google’s machine learning technology.
Google has never shy’d away from asking for raw audio via file uploads, API connections, web microphones, and via basically any hardware/software that can pay the Speech to Text fee of $0.006 USD per 15 seconds of transcribed audio — and the first 60 minutes is always free. Google has also long been a leader for user-centric privacy controls and lets users listen and delete all their recordings sent to their services. They haven’t however, in any significant way, explained their 3rd party audio dark metadata retention policies and any changes in their policies due to GDPR.
Here’s Google’s public Cloud Speech to Text webpage showcasing the features that ensure 3rd party audio dark metadata is always sent to Google prior to any sort of on-device parsing:
Microsoft’s Bing Speech API Similar to Google and Amazon — Firehose Audio Ingestion of 1st and 3rd Party Audio Dark Metadata
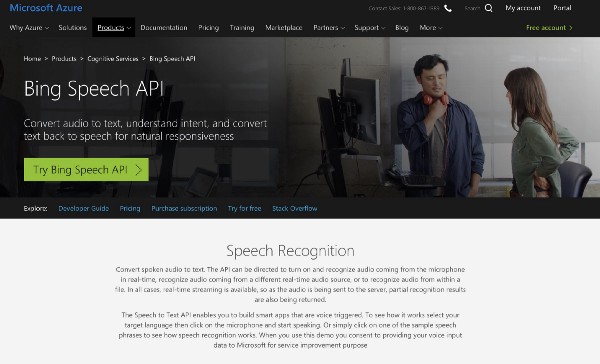
Microsoft’s Bing Speech API is structured almost identically to both Amazon and Google. Audio data is sent to Microsoft servers prior to analysis. Their Cortana devices were also built similar to Google and Amazon, with the voice data being transferred to Microsoft servers for processing.
News reports have also pointed out that Microsoft’s Xbox has a app they produced called Voice Studio that listens to background sounds that come through microphones as people are gaming on Xbox. The same article also explained several other audio dark metadata uses-cases have been developed by Microsoft and Google, with the Microsoft audio dark metadata collection and filtering in airports having potential privacy implications for business travelers:
Companies are also designing voice recognition systems for specific situations. Microsoft has been testing technology that can answer travelers’ queries without being distracted by the constant barrage of flight announcements at airports. The company’s technology is also being used in an automated ordering system for McDonald’s drive-thrus. Trained to ignore scratchy audio, screaming kids and “ums,” it can spit out a complicated order, getting even the condiments right. Amazon is conducting tests in automobiles, challenging Alexa to work well with road noise and open windows.
NOTE: For the same reason this research doesn’t include every company working with audio NLP (Baidu and Samsung are doing very interesting things), Microsoft was largely ignored due to their current U.S. market share. It is clear they operate in very similar ways to both Amazon and Google, and most news accounts would point to Apple as the outlier.
Apple’s Privacy-Centric Strategy for Local Audio Dark Metadata Processing and Filtering via HAL

As reported by the New York Times last month, Apple is focused on Natural Language Processing (NLP) without compromising privacy — something that competitors have balked at:
Apple has taken a strong stance on protecting the privacy of people who use its devices and online services, which could put it at a disadvantage when building services using neural networks.
Researchers train these systems by pooling enormous amounts of digital data, sometimes from customer services. Apple, however, has said it is developing methods that would allow it to train these algorithms without compromising privacy.
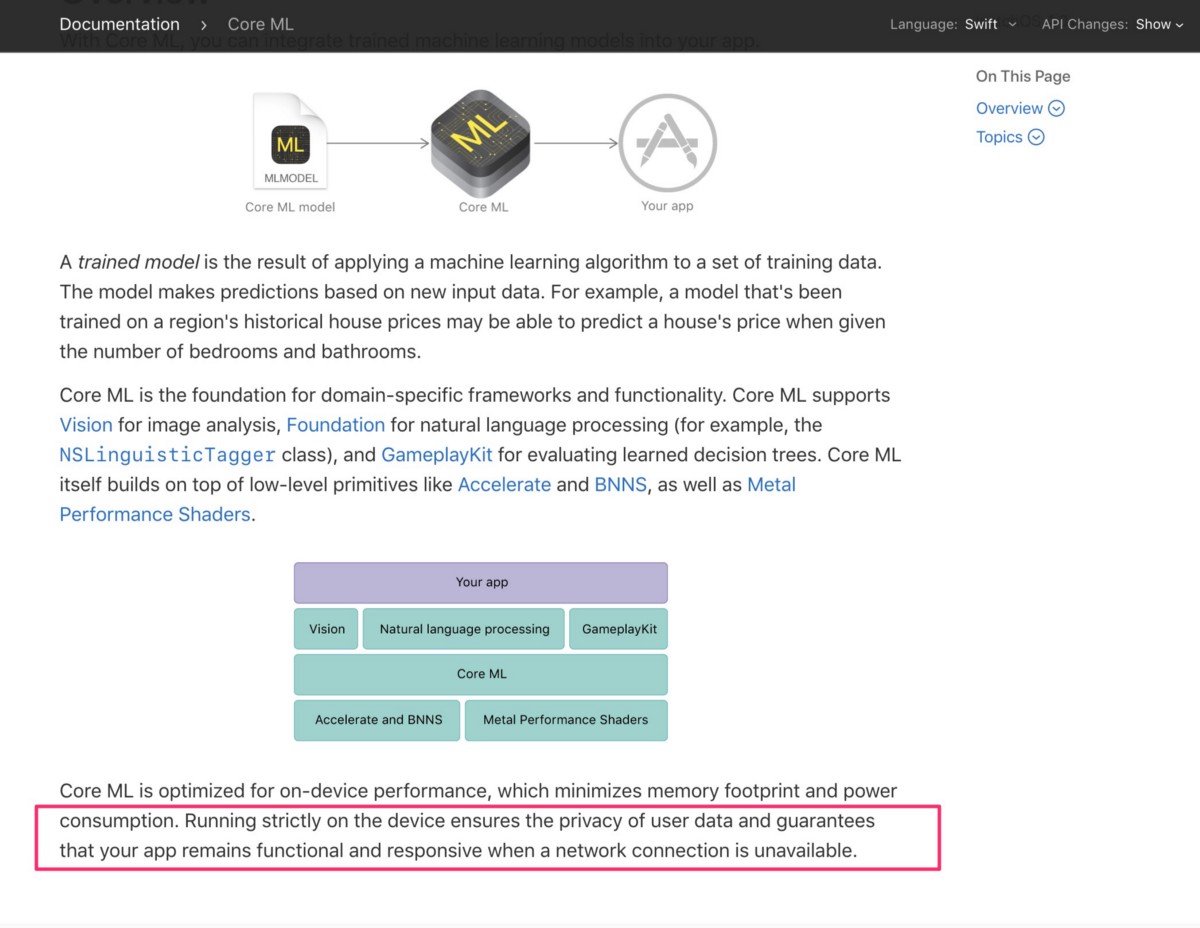
Apple provides 3rd party audio NLP developer tools in a very unique way — radically different than Amazon, Google, Microsoft and most of the industry. Apple only provides audio NLP through their hardware and describes it on their CoreML about page, “Running strictly on the device ensures the privacy of user data.”
Here is a screen shot from the Apple CoreML page describing how they protect user privacy by only providing audio Natural Language Processing through their hardware devices:
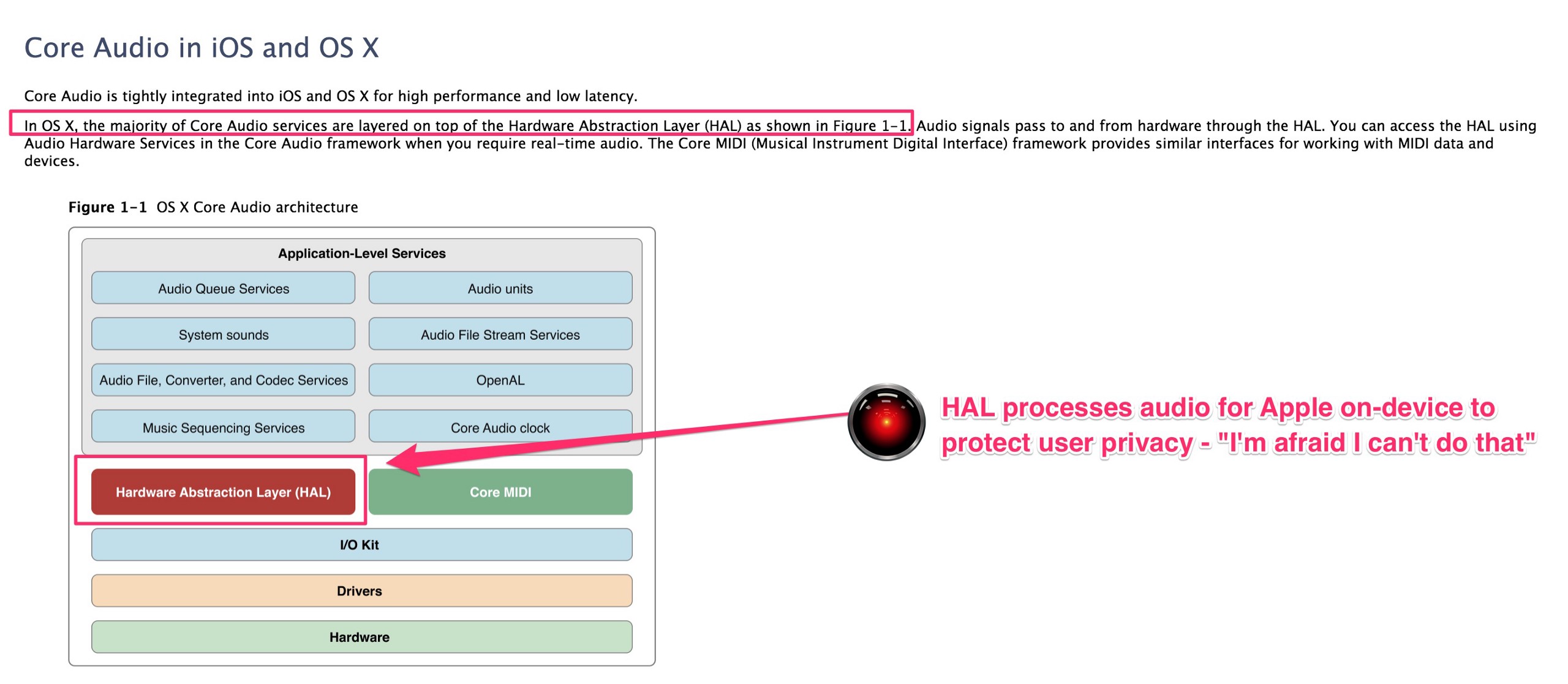
In the developer resources for Core Audio, Apple names this privacy layer the Hardware Abstraction Layer, or HAL, writing:

“In OS X, the majority of Core Audio services are layered on top of the Hardware Abstraction Layer (HAL) as shown in Figure 1–1. Audio signals pass to and from hardware through the HAL.”
Apple’s HAL — the real product of Apple AI
Apple acquired dark metadata company Lattice Data in Spring 2017 and on-device AI processing experts Perceptio in 2015 have been deploying a version of Stanford’s Deep Dive project in their ironically-named Hardware Abstraction Layer (HAL). Lattice and Perceptio IP are core elements of HAL along with likely hundreds of other team-members and IP from other less-visible acquisitions. The production of AI-centric co-processors like HAL has increased in recent years and is likely to continue growth as the full privacy implications of GDPR is seen-out.
Beyond the core privacy benefits, Apple’s HAL architecture provides a platform to create fully segmented speech NLP algorithms that are able to break the speaker-independence curse that occurs from monolithic speech to text training — aka the “not everyone sounds like a developer from San Francisco” conundrum. It’s obviously slowed down their entire development process, but conceptually, their goal is clear.
This concept was explained by Apple to Tech Crunch in 2015 when other privacy concerns were raised, with HAL providing pseudo-security for false wake-words:
Instead, audio from the microphone is continuously compared against the model, or pattern, of your personal way of saying ‘Hey Siri’ that you recorded during setup of the feature. Hey Siri requires a match to both the ‘general’ Hey Siri model (how your iPhone thinks the words sound) and the ‘personalized’ model of how you say it. This is to prevent other people’s voices from triggering your phone’s Hey Siri feature by accident.
Apple also explained their use of random IDs instead of personally-identifiable information when sending their Siri data to their servers, which likely is similar to how they handle 3rd party audio dark metadata:
Of course, as has always been the case with Siri, once a match is made and a Siri command is sent off to Apple, it’s associated with your device using a random identifier, not your Apple ID or another personalized piece of info. That information is then ‘approved’ for use in improving the service, because you’ve made an explicit choice to ask Apple’s remote servers to answer a query.
Here is a screen shot from Apple’s Developer portal showing this privacy and segmentation architecture of HAL within the scope of Core Audio:
Apple and 3rd Party Audio Dark Metadata — Hardware Dominance Supports a Privacy-Centric NLP AI Strategy
For Apple, post-Lattice and Perceptio acquisitions, the obvious use-case for optimizing massive amounts of audio dark metadata comes from their hardware dominance . iPhone is growing exponentially faster than Android — in the fourth quarter of 2017, Apple’s iPhone X generated over 5x the profit of 600 Android devices combined. Also, a recent 2018 poll of U.S. teenagers showed growing demand for iPhone’s with 84% of teens stating their next phone would be an iPhone.
Further to this point, Apple CarPlay is now available in over 300 car models and 6 aftermarket audio systems — and Apple has been racking up numerous CarPlay partnerships with huge audio app developers including WhatsApp, Spotify, Pandora, NPR and MLB at Bat.
Google has lagged behind with Android Auto, which still only has wireless available for people using Google’s own phones (wired connections for most other models). Google does however regularly update their Android Auto website and are obviously committed to growing that sector in a significant way — but through a totally different deployment and privacy architecture.
With Americans spending, on average over 290 hours per year on average in their cars, it remains a significant opportunity for NLP systems.
Apple Files Patent for Audio Dark Metadata Retargeting Ads and Bridges Air-Gap for Offline-Online Retargeting Ads
Read all of Apple’s pending patent here to get the full-scope of their real-world to online retargeting technology: “Accessing radio content from a non-radio source”
If the early 2000’s were dominated by Search and Product Retargeting, the 2020’s are set to be dominated by real-world retargeting — and Apple is starting with radio retargeting.
They aren’t just deploying “you may have listened to” retargeting, these ads will know the second you stopped listening from one device to encourage picking back up at that exact second on another device — and many other use-cases could be on the horizon…
Apple created the diagram here showing how they are planning to monetize their iPhone and CarPlay audio dark metadata to encourage someone to “finish listening to x show” when they get out of their car.
Here’s a flow chart for the logic behind the “finish your show” retargeting feature, as described by Apple:
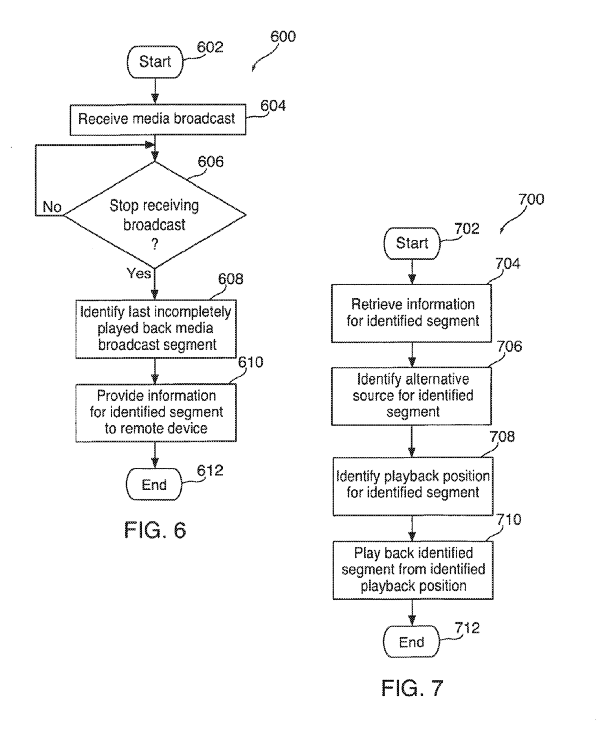
In response to detecting that a user has not finished listening to a broadcast segment (e.g., a radio segment), an electronic device can automatically identify and access an alternate, non-broadcast source for the same broadcast segment (e.g., a corresponding podcast episode). Using the electronic device, a user can play back the segment from the non-broadcast source, starting playback at the last position of the broadcast segment when the user stopped listening to the broadcast.”
Apple described this Radio-Retargeting (Where you left off) patent and vaguely described the potential use-cases for both music and talk-radio:
For example, a media broadcast can include a succession of different media items (e.g., different songs). As another example, a media broadcast can include a succession of segments (e.g., a succession of conversations or interviews with different guests).
The patent specifically outlines a use-case for Apple’s CarPlay to let a user continue listening to a podcast after they turn off their car and get to their computer:
A user, however, may not always have access to the radio broadcast stream or media broadcast stream provided by a content provider. For example, communications circuitry or radio tuning circuitry of an electronic device may not receive a radio broadcast (e.g., as the device goes into a tunnel or in an area that radio waves cannot access). As another example, communications circuitry can move too far from a broadcast source (e.g., a communications node of a communications network) to receive broadcast data. As still another example, the user is required to turn off the electronic device (e.g., turn off a car radio upon leaving a car). If a user is listening to a particular media item or radio segment of interest, the user may not be able to finish listening to the segment, and can miss parts of broadcast content before a second electronic device can receive the broadcast stream (e.g., the user turns on a radio in their house or office).
Previous News Reports Confirmed the 1st-Party Processing and Privacy Architecture of Apple, Amazon and Google — Less Clear Policies on 3rd Party Audio Dark Metadata or “Background Noise”
Wired’s December 2016 article on speech NLP AI reported that Apple uses a random string of numbers with 6-month data retention, whereas Google and Amazon were storing all audio data until a user decides to delete them. The original article did not mention 3rd party data so it’s unclear what happened to the dark metadata in both of these scenarios. It’s clear however that Apple has taken a divergent approach to audio AI privacy:
While Apple logs and stores Siri queries, they’re tied to a random string of numbers for each user instead of an Apple ID or email address. Apple deletes the association between those queries and those numerical codes after six months. Your Amazon and Google histories, on the other hand, stay there until you decide to delete them.
Audio AI Breaking the Air-Gap — 3rd Party Audio Dark Metadata is Worth Billions
https://giphy.com/gifs/glas-2018-xThtatVgZVprKd3UEU/tile
Here’s a scenario — for all intents and purposes, let’s assume that Amazon doesn’t convert background audio into dark metadata on-device and reject any non-primary-speaker audio prior to that data going into their servers (or perform some type of anonymization after being stored).
Picture for a moment, someone is sitting at their office desk listening to some music from their Amazon Echo speaker they purchased using their business email address — they decide to ask Alexa to switch to Crazy in Love from Beyoncé — and at the same moment they are asking to load up one of the great jams of our generation — someone in their office two cubicles down yells out, “Ya but it’s HQ’s fault we aren’t going to make the release this quarter!” If that audio snippet were passed into Amazon’s servers, with the geotagging of the speaker putting it at the businesses satellite office, any audio dark metadata AI models and translations would have all the information it needed to determine that a public company was about to miss revenue projections.
If machines can hear 3rd party audio dark metadata that includes corporate secrets, and if machines are also buying stock from public data, what protections will keep the machines from trading stocks on the 3rd party audio dark metadata?

Another potential scenario is that in any large crowd, if someone activates Siri or any other speech AI system that records background noise, there are people being recorded who have not agreed to the Terms of Service of that company — and if that data is then being parsed and passed directly back into the servers of that company without any effort to protect the speech of a non-user — that’s the type of unintended surveillance that will eventually have some sort of “Cambridge Analytica” moment that forces Congress to step in and regulate the storage and processing of 3rd party audio dark metadata. This moment of regulation is the moment that a privacy-last NLP ML/AI system will be forced to go completely offline and rebuild the business and training data model from scratch.
There is a significant moat around speech recognition and the challenges to build speech personalization at scale while protecting privacy, and as the race gets further along, we’ll start to see these moments where AI and privacy collide, and the public will see which companies had the foresight to prepare for those moments.
April 2018 — John Giannandrea Jumps Ship from Google AI to Lead Apple AI
Last month, Google’s AI chief John Giannandrea was unexpectedly hired by Apple to lead their AI work, reporting directly to CEO Tim Cook. From some perspectives, the decision is inexplicable — who would bet on Apple over Google or Amazon in the race for AI dominance? The timing with the global discussion on privacy, user data and implementation of GDPR should make a lot of investors ears perk up…
In an email to staff members obtained by The New York Times, Mr. Cook reported on the hire stating, “Our technology must be infused with the values we all hold dear…John shares our commitment to privacy and our thoughtful approach as we make computers even smarter and more personal.”
The Wildcard: Inevitable Governmental Regulations, and the May 25th, 2018 GDPR Implementation
The EU General Data Protection Regulation (GDPR) creates new rights for individuals in Europe and has extremely strict regulations to protect user privacy. It is forcing companies to comply with strict data retention policies and gives individuals new rights of appeal and investigation. When exploring the implications of GDPR, most use-cases have focused on 1st-party data retention, but these policies could apply to 3rd party audio dark metadata and could open up a litany of liability for certain companies providing these very “generous” speech to text NLP API’s for developers while scooping up the audio dark metadata without any attempt to filter out 3rd party data.
A few of the new individual rights from GDPR was organized by ComputerWeekly as they analyzed it in the run-up to implementation last year:
Under GDPR Article 22, the individual will have the right to challenge the way these algorithms work and the decisions they make. This introduces a new approach to seeking consent, as businesses must get permission to use personal data and to process it in certain ways.
Article 17 of GDPR introduces the “right to be forgotten”. Unless a business or organisation can show a legitimate reason to retain an individual’s data, that person can request the information is deleted by the business without “undue delay”, which may represent a significant challenge for many organisations.

As the full implications of the GDPR implementation are observed, and as the U.S. continues to debate new privacy and data retention legislation, there needs to be additional discussions about whether companies can be held liable for their 3rd party audio dark metadata collection and retention policies. Should a company be required to remove 3rd party audio data before storage? Should a company be required to remove 3rd party audio data after storage? Where is the line?
It is extremely challenging to acquire, store and analyze trillions of pieces of audio dark metadata in real-time while protecting user privacy. None of the companies mentioned in this article can be completely faulted for ignoring this concept in their public messaging, because technically-speaking it’s still early-days with this type of dark audio metadata classification. Fortunately, on-device, speaker-dependent processing through architecture like HAL is challenging the industry and their “store-first” mentality. Streams of 3rd party audio dark metadata are being collected right now by potentially dozens of companies, with likely very few of them even considering Apple’s on-device privacy-centric approach.
Congress only recently debated the Cambridge Analytica scandal and data acquisition through Facebook’s app permissions, which has gone on for nearly a decade. It’s unclear if and when they will fully understand audio AI systems and the importance of a company providing clarity about how they handle that type of 3rd party data. Once members of Congress and the EU realize that 3rd party audio dark metadata conversations are currently being captured and stored by other user’s devices without 3rd party consent, someone will need to test this current 3rd party audio dark metadata environment through the agreed-upon legal channels in GDPR and other governmental authorities.
What other problems should Apple, Google, Amazon, Microsoft and other speech recognition AI companies work on? A few questions to consider…
What dark metadata amalgamation strategies could create unique products? This is the trillion dollar question that will need to be answered for decades.
Work with co-processors has gone on for years and production since at least 2008 — which microchip manufacturers will be the first to develop and market HAL competitors specifically for it’s privacy features?
How will Apple ensure that HAL and their privacy-centric device processing strategies stay ahead of the game? Which other device and chip manufacturers are best posed to compete or already architecturally prepared?
What types of other on-device privacy filtering needs to occur from companies like Apple to protect 3rd party audio dark metadata from being exploited?
How are companies and courts going to define their own efforts to meet the GDPR’s attempt to create an environment of “pseudonymization”?
How do 1-party and 2-party recording consent laws (patch-work quilt regulations across the U.S. and world) impact 3rd party dark audio metadata collection and storage? This is a great report from Stacey Gray from April 2016 for the Future of Privacy Forum that covered this in some new ways, particularly the impact on data retention due to HIPAA. If 3rd party audio dark metadata could be geotagged to a hospital, does that mean it automatically needs to be rejected?
Should Congress hold hearings on audio dark metadata and the impact on 3rd-party privacy from NLP AI systems?
Should companies keep audio of their users when captured on another users device they control (ie family plans?)? Where is the line for 2nd party audio tracking?
Which company will be the next to follow Facebook, who announced their Data Abuse Bounty Program on April 10, 2018? How do you find and expose your data abuse and internal data problems?
FINAL WRITERS NOTE: During this reporting, the perceived male gender of “HAL” and perceived female gender of “SIRI” annoyed me greatly. Personally on my Apple device I have a British male Siri voice so that when it does poor translations I’m not yelling at a woman. It’s important for all of these companies working with voice to text AI to recognize the gender bias deeply rooted in their technology and look for ways to prevent their bias — this is crucial to prevent the looming SkyNet future. Everyone working in AI should read about algorithmic bias and algorithmic oppression — one of the most eye-opening and important books on the topic is by Safiya Umoja Noble, Algorithms of Oppression — please consider picking up a copy on NYUPress, B&N, or Amazon. Dr. Noble is very active and available to give presentations — every company working with AI needs to ask for her help.
Got other feedback or a fun project? Hit me up on Twitter @thezedwards on Linkedin or via my company website @ VictoryMedium.com if doing cool work✌
(Amazon, Apple, Google, and Microsoft were sent a request for comment on this article over a day before publication. No official comment was received as of publishing but I’ll update this if/when statements arrive. No payment was solicited or made in connection with this article. If any company mentioned has any corrections or problems don’t hesitate to reach out via zach[at]victorymedium[dottttt]com and i’ll get on it asap. Any additional comments that you’d like to have added send to the same email or message me here on Medium. Thanks for reading and thinking about 3rd-party audio dark metadata privacy and product implications.)
Image credits all link to giphy.com unless noted
Illustration Blink GIF by Kochstrasse
Ignore the Big Lebowski GIF by unknown
Sad Black Friday GIF by JON
Congressman GIF from The Count
2001 A Space Odyssey GIF from Top 100 Movie Quotes of All Time
John Candy from Planes, Trains and Automobiles GIF by unknown
Regina George Privacy from Mean Girls GIF by unknown
Highway time-lapse GIF from Funny Junk
Apple Park Satellite View image from Wikipedia.com, image from Planet.com
Crane Shipping GIF by The Chosen One
Final credit goes to this helpful article from the Siri Team @ Apple, “Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant” via Apple.com
Recent Comments