6/6/18 Update — Click here to watch a summary video of this proposal — the video is 45 minutes long but attempts to explain some of the more complicated details. Thanks for watching and reading and all the feedback!
GDPR goes into effect today, May 25th, 2018, and creates a massive shift in global expectations for user privacy.
Users have made it clear that the state of advertising and tracking is unacceptable, publishers are going broke, and the market continues to swing more and more out of balance with Google, Facebook, Amazon and Apple making record profits. And until today, companies have not faced any real financial incentives to pseudonymize data.
Though many perceive GDPR as effectively outlawing certain data markets, the implementation of GDPR also poses a unique opportunity to remake markets and monetize data — without compromising user privacy and while promoting competition and undermining existing monopolies.
Before you read any further, I’d strongly recommend watching this short video, below, from Bloomberg News about ETF Markets and how they stabilize prices and create new value. This will provide a good primer on the proposed Cookie Exchange concept and how an ETF Market built on the arbitrage of pseudo-cookies can be used to automate online advertising targeting while stabilizing costs.
https://www.bloomberg.com/news/videos/2016-03-07/what-is-an-etf
“There are now over 6,000 ETFs on 60 exchanges and ETFs exist for everything from corporate bonds to gold bars to oil…” — Click here to watch the 2-minute video on Bloomberg.com.
The Genesis of the Cookie Exchange
In my early 20s I was a professional poker player living in Vegas. I’ve always loved proposition bets — basically any bet made outside a traditional card game or casino game. I left poker over a decade ago, but the data-driven approach to game theory has served me well during my career in digital.

I had a bit of a eureka moment about a year ago when I thought to offer a fellow marketer a bet:
“I’’ll bet you $50 with Texas-sized odds @ 3:1 that you can’t beat $1.75 cost-per-click @ $45 cost-per-customer-acquisition for the Facebook Audience ‘Newly Moved’ and a budget of $1k.”
At that moment, I realized a potential market existed for the exchange of cookies. And we could create that market with incentives, similar to emerging market ETFs, to stabilize ad-click costs, and manage global advertising targeting through automated algorithms. This pseudo-arbitrage would reduce costs, promote data sharing, and encourage cooperation through a variation of the Shapley Value formula. Delivery of ads would be optimized with variations of the multi-armed bandit algorithms and the Bayesian algorithms that Microsoft and other companies use to historically optimize click-through-rates for ads. The tech is here, just being applied for a different market.
This new Cookie Exchange would not only provide massive new audiences for brands and companies by opening walled-gardens into public exchanges, but by also harmonizing GDPR’s pseudonymization and right to be forgotten principles with the digital world’s demand for data.

What is “Pseudonymization” and Why Does it Matter?
GDPR effectively requires companies to either anonymize user data or pseudonymize user data, if they intend to use it beyond the originally authorized use (See GDPR, Article 6, Section 4). Wikipedia describes pseudonymization and it’s slight difference from completely anonymous data:

Pseudonymization is a data management and de-identification procedure by which personally identifiable information fields within a data record are replaced by one or more artificial identifiers, or pseudonyms. A single pseudonym for each replaced field or collection of replaced fields makes the data record less identifiable while remaining suitable for data analysis and data processing.

The major difference between pseudonymized data and any data that is tied directly to a user’s personally identifiable information, is the fact that the latter is permanent.
Pseudonymized data allows a user to essentially tell advertising networks, “I want to see ads on X topic or product” — and then when the usefulness of that has expired, the user could delete their cookie and start over with a fresh profile. The “pseudonymizedID” associated with every cookie could be deleted and then a totally new pseudonymizedID could be acquired by a user to start over with the data they are sending to advertisers.
Some core social networks like Facebook and Google would provide significant amounts of audience data for this initial Cookie Exchange (and the Shapley Value Formula accounts for that, more below). In order to have a stable inventory of data and ads, organizations would be able to “back-fill” their own targeting data into a pseudonymized cookie, but only putting that data into the device and browser a user was currently using — essentially every device generates unique pseudonymized cookies and they are constantly expiring both from user action, but also due to jurisdiction requirements.
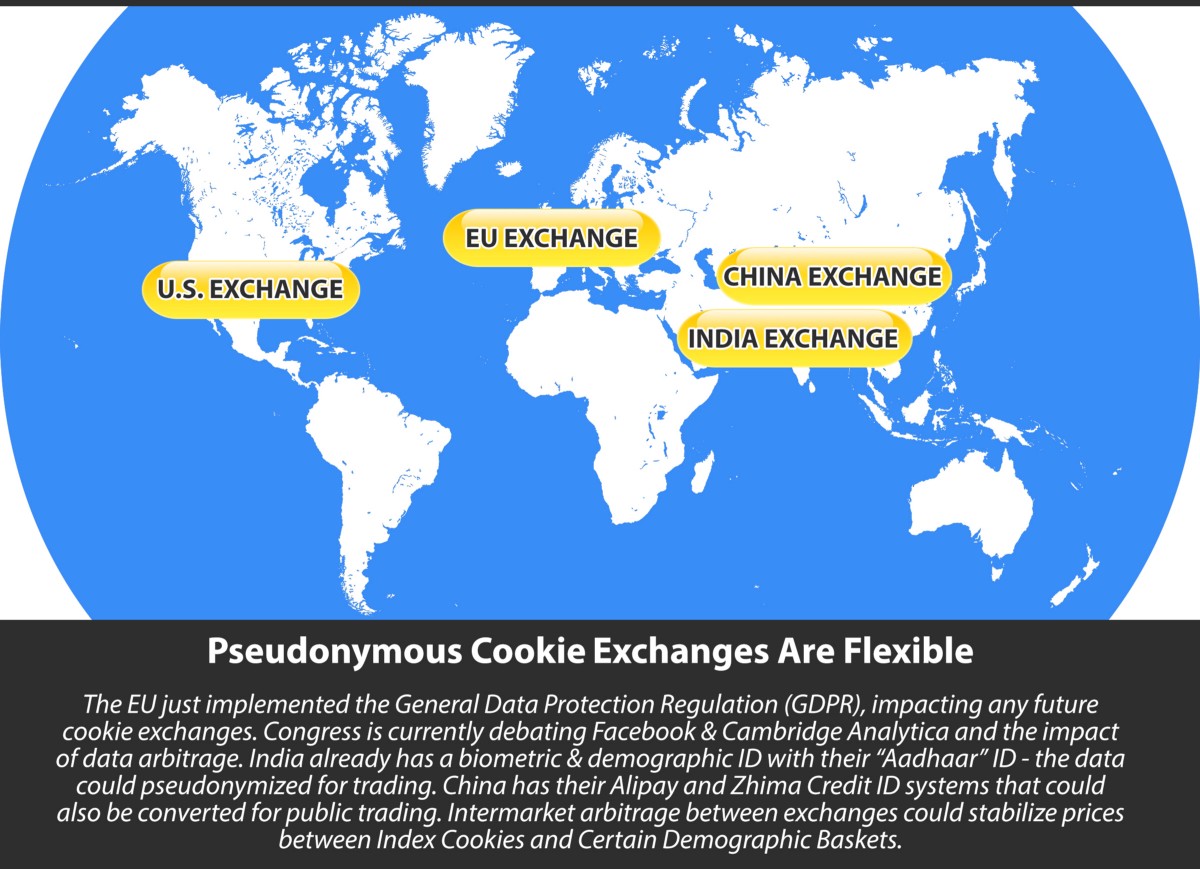
There are many strategic benefits for using pseudonymized data, with market automation being paramount among them. Data that contains PII literally can’t be traded in the EU en-masse since GDPR was passed — so the only way to actually service a stable ads market is to support pseudonymized cookies and efforts to let users clear them at will and networks to refill them and share them for ads without compromising the user’s privacy.
The Public “Cookie Exchanges” via ETF Markets (an arbitrage market that reduces and normalizes costs) could be created to properly reward the creation of this pseudonymized cookie data.
Digital Cookies Used for User Tracking Have Value

One of the most important parts of the new Cookie Exchange is acknowledging the existing value in all of the cookies (user data) that websites, apps and other technology are currently giving away to a couple companies in Silicon Valley.
The vast majority of websites act as share-croppers and receive $0 revenue from the data they provide the current dark ads market. And even the biggest publishers don’t know how to track their data leaks, or how to ask for their money.
But that doesn’t need to be the case. The Shapley Value Formula, currently being used for Google’s newest data-driven attribution models, if structured slightly different, could create a new cooperative publisher environment where dozens of companies, publishers and content creators could receive money from every advertising click.
The Shapley Value is a game theory concept driven by the inherent value of cooperation. Under the Shapley Value, collaborators with different needs and different contributions maximize their return by ensuring that each actor gains as much or more as they would have from acting independently.
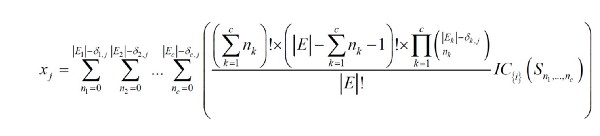
The Cookie Exchange version of the Shapley Value Formula was originally developed to share costs of natural gas transmission lines across diverse customers, and was published in a paper by Olivier Massol and Axel Pierru in 2008.
(Note on the Shapley Value Formula: cooperation algorithms and game theory are discussed in a wide variety of oil and gas papers and by other academics — they should be weighed against Massol and Pierru’s formula, and it would seem certain that even MP’s base formula would see many changes before being deployed into the Cookie Exchange. Latency of the formula execution will be one of the key differentiators — the Massol and Pierru formula can split cooperatively across 100 segments (publishers) in a thousandth of a second. Massol has published another paper on Shapley optimization , but in general, the research into cooperative markets is too vast to get into deeply in this article.)
Why Google Uses the Shapley Value Formula for Attribution and Why the World should Use it to Cooperate on the Internet
Google uses the Shapley Value Formula to determine cooperation between sources of a conversion and attribute revenue proportionally to each of them. Steven Sonnes from Path Interactive described Google’s strategy as a “cooperative game theory”:
In 2013 Google unveiled the Data-Driven attribution model for Google Analytics Premium, and in 2014 they released it in AdWords. …Data-Driven Attribution uses an algorithm based on a concept from cooperative game theory called the Shapley Value. The Shapley Value was developed by the economics Nobel Laureate Lloyd S. Shapley as an approach to fairly distributing the output of a team among the constituent team members. In the case of Data-Driven Attribution, the “team” being analyzed has marketing touchpoints (e.g., Organic Search, Display, and Email) as “team members,” and the “output” of the team is conversions. The Data-Driven Attribution algorithm computes the counterfactual gains of each marketing touchpoint — that is, it compares the conversion probability of similar users who were exposed to these touchpoints, to the probability when one of the touchpoints does not occur in the path.
In plain English, the Shapley Value rewards market players who collaborate with each other, to share value, when such cooperation ensures the same or greater gains than if they acted independently.
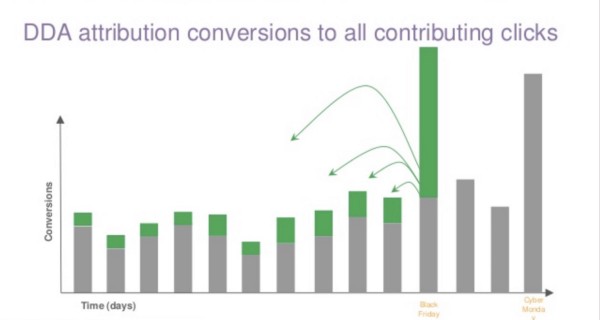
Google DDA Attribution (Shapley Value) Accurately Gives Credit for Past Touch Points
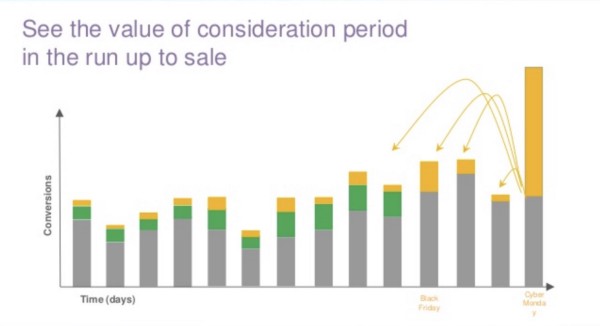
Sabrina Garufi, Agency Development Manager at Google, gave a Google DDA Attribution presentation for Click Consult’s Benchmark Search Conference 2017 — view the full presentation here or embedded below.
Slides 19 and 20 give a simple high-level view of how purchase conversions occur from advertising touch points over days and weeks. Google DDA Attribution, using the Shapley Value to encourage cooperative and balanced attribution, splits one sales conversion into dozens of pieces so that each advertising touch point is appropriately credited.

If Google uses the Shapley Value to credit “traffic sources” (but not give them any revenue) why can’t we create a new market that provides monetary value for the “conversion assists” on a user’s pseudo-cookie?
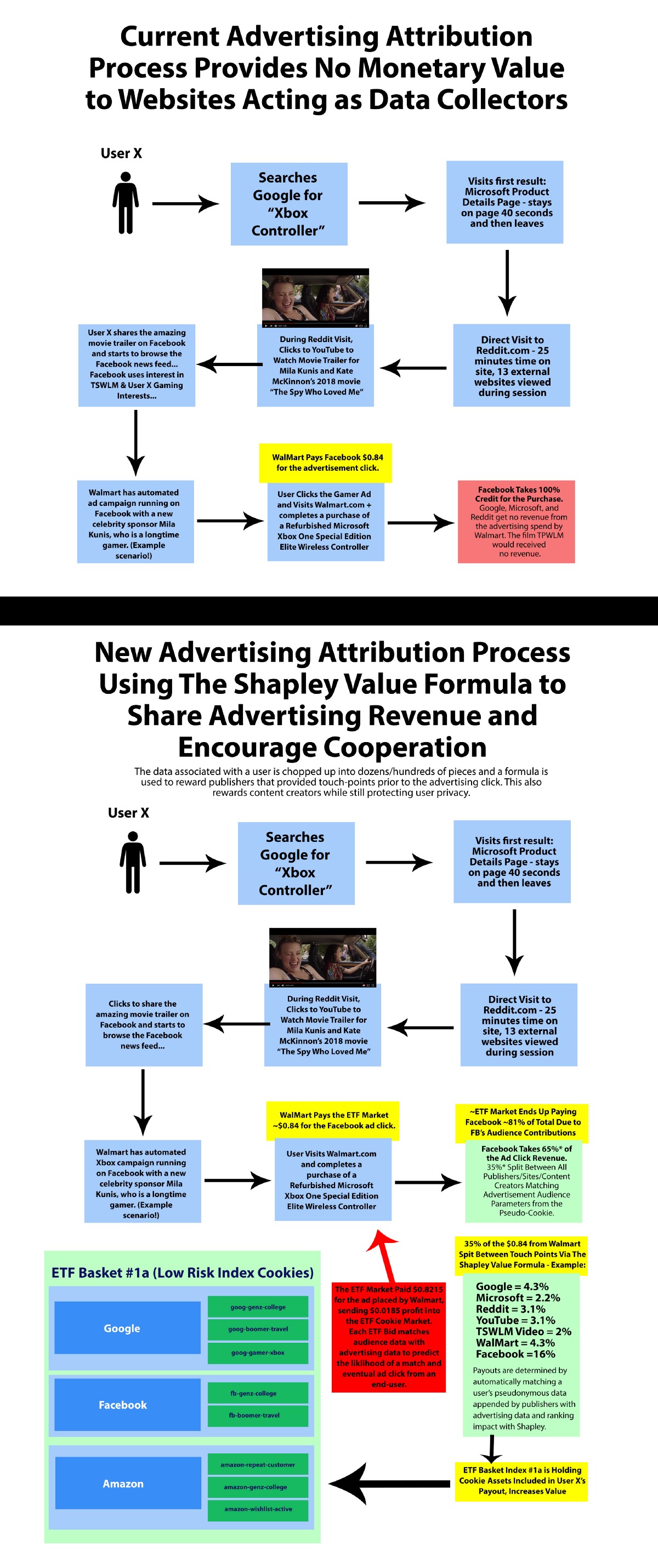
Security of the Cookie Exchange from Current “Same-Origin” Tech Standards — Pseudonymized Cookie Data Passing Between Domains and Businesses Securely via “Cross-Origin Resource Sharing” (CORS) via the “withCredentials” Property
Dealing with internet/web cookies is complicated, and many parts of this Cookie Exchange may require some tweaks to schema standards. Fortunately, the core tech standards already exist for both Cookie Exchanges and for the pseudonymized cookies to pass between separate websites and unique businesses.
The Same-Origin Wikipedia article gives a good explanation about this type of internet security, but if you’ve ever heard of “Cross-Site Scripting” (XSS) or wondered how banks and secure websites keep your information private — they do it through this core security built into all internet connections and devices. Here’s how Wikipedia describes how one website prevents you from being attacked by another:
In computing, the same-origin policy is an important concept in the web application security model. Under the policy, a web browser permits scripts contained in a first web page to access data in a second web page, but only if both web pages have the same origin. An origin is defined as a combination of URI scheme, host name, and port number. This policy prevents a malicious script on one page from obtaining access to sensitive data on another web page through that page’s Document Object Model.
This core Same-Origin Policy has evolved for some “wiggle room” ($$) to allow for “Cross-Origin Resource Sharing” (CORS) — which allows for certain types of data (cookie files and some other types of files) to be passed between websites and other systems.
It’s clear that the schema for the Cookie Exchange would need to be debated for consensus among publishers, but there are no technical limitations to pass pseudonymized data between domains via a cookie text file.
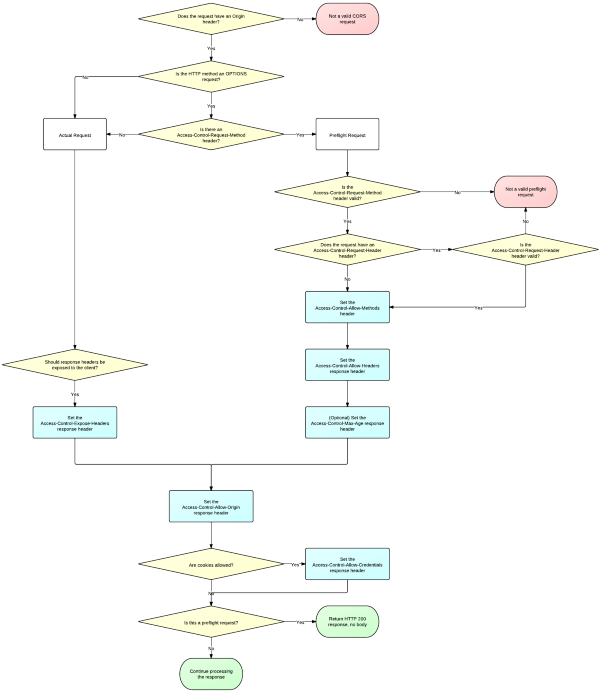
More specifically, CORS would use the “withCredentials” property to send and set cookies between domains. HTML5Rocks’ Monsur Hossain did a fantastic job with the article on CORS and the deployment of “withCredentials” to set cookies. To the left on this page is the flow chart from Hossain that shows how one domain asks another domain for cookie information and then has it passed securely:
There are a bunch of other great resources on CORS, including from NCZOnline, HTML5Rocks, Brian Prom, Stack Overflow, Cognizant’s Quick Left, and Mozilla.
CORS is part of the magic sauce behind a Cookie Exchange actually passing data between websites…but one of the most exciting things about the Cookie Exchange is that websites aren’t the only thing that can append data to a cookie…

How the Cookie Exchange ETF Market Would Trade Cookie Indexes and Baskets
If you haven’t already, make sure to check out this video from Bloomberg News about ETF markets.
How would a banker and anyone participating in an ETF Market stabilize prices and automate targeting?
In a dramatically simplified example, basically a banker says, “I only think this advertising audience is worth a nickel based on past data … but then if an advertiser/company pays 10 cents, the market pays out 5 cents (with a portion going into the Shapley Value Formula as a market fee).
The important part of this arbitrage auction is the balancing act that a ETF market creates and how the data is public — as the ETF market makes money, advertisers drop their bids automatically to save money. The banker is not betting on a company or any audience, they are betting on the value of a piece of data that a company or individual created, and the potential for that piece of data to match up to an ad’s metadata and pay out via the Shapley Value formula. The optimized matching of the data creates value, not any one piece of the data itself.
Through this process of bidding, matching, payouts and renewal of the inventory in the marketplace, optimization at a global scale can occur so that advertisers only add a modicum of whitelist/blacklist targeting customizations, and the arbitrage bidding would optimize the rest.
Bloomberg describes this automated bidding in an ETF as a stabalizing factor for price:
This is an opportunity for you, the bank — a balancing act. If the ETF’s price is above its value, you can make money by adding more bits of stock to the fund: Buy the stocks for the cheaper price, sell the ETF for the higher price. You can also do the opposite: If the ETF’s price is below its value, you can return shares of the ETF in exchange for the stocks it stands for, which you can sell for more.
The ability to create and redeem shares gives big investors and market makers an incentive to arbitrage the price of the ETF with the fair value of the stocks in the basket. This continuous arbitrage is why an ETF’s price on the exchange is typically very close to the value of the securities in the basket. So you get paid to get things more balanced; the difference is your prize money. This makes the ETF more useful and reliable to everyone. Congratulations, you’re a market-maker arbitrageur!
Here’s a visualization of this balancing effect in an ETF Market:

Picking Winners and Losers in the Cookie Exchange
Every website is different, and different types of users visit different types of content — but every page view generates value for someone. Every time a webpage loads, data is being sent to companies who monetize it. This is important to understand — small amounts of money are generated from even just one user loading one webpage.
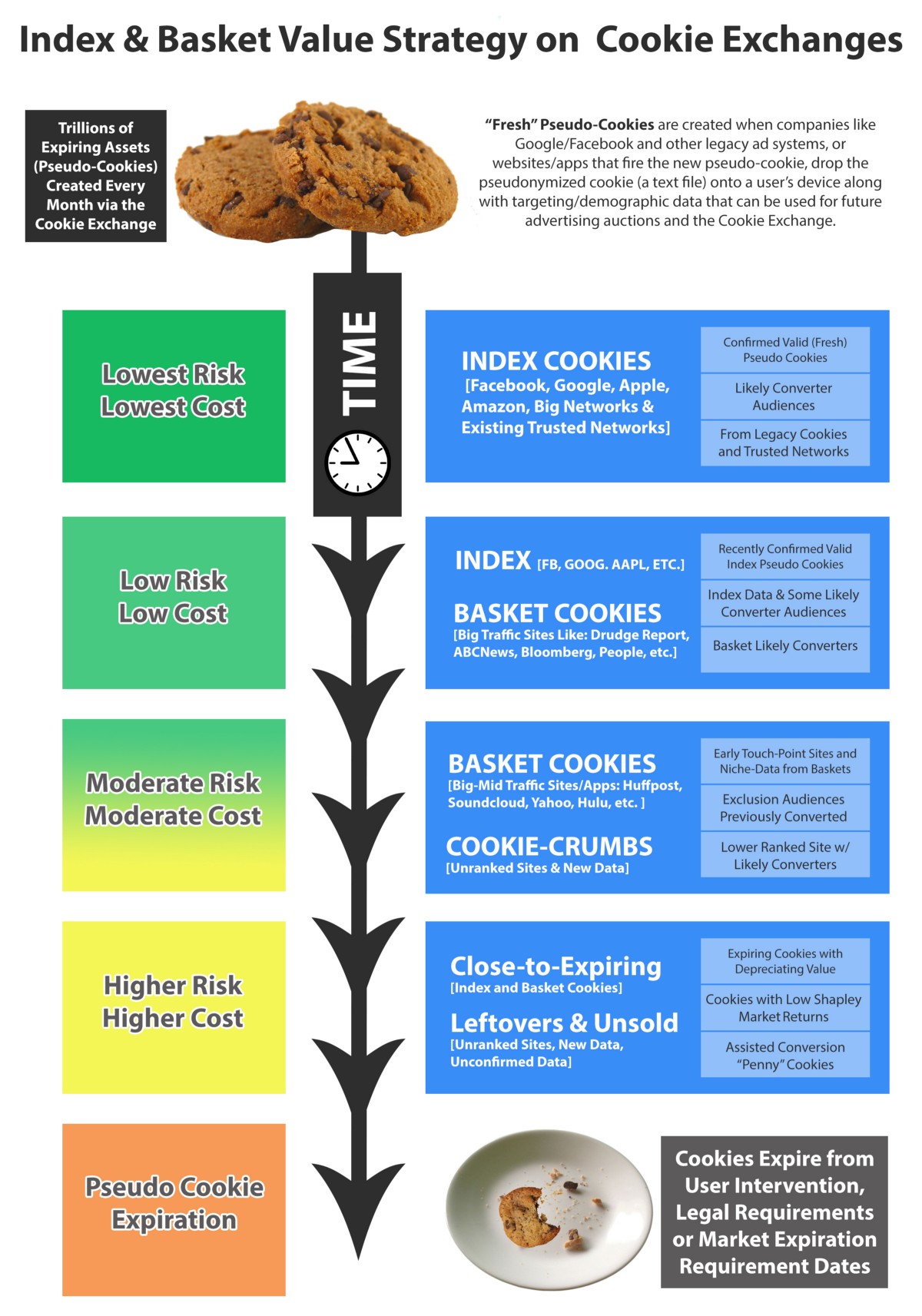
The important question is: how is that value organized for a market?
In the Cookie Exchange market, the data that is appended to a user when they load a website is then passed into advertising platforms, and based on the targeting and bidding of the ads auction, a user is shown a specific ad. When the targeting metadata in the ads match to user metadata in a pseudonymized cookie, those publishers providing each piece of data are paid out from a user clicking on that ad based on the total number of matching pieces of metadata from the ad click.
The combination of billions of websites and thousands of potential targeting criteria creates a complex web of value, but it’s still finite. The question then becomes, what makes a cookie less valuable? How do you determine investment strategies?
Indexes and Baskets in a Cookie Exchange
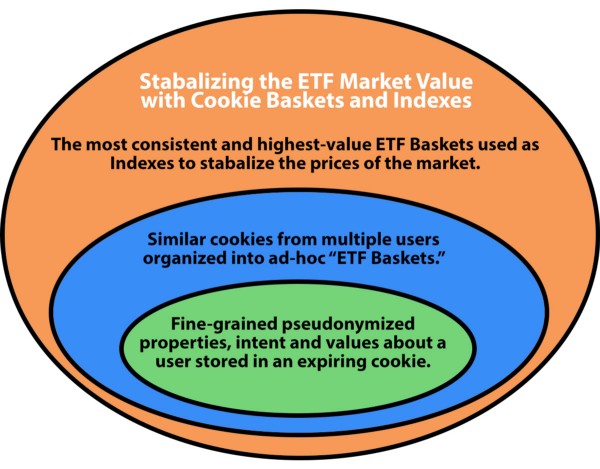
In order to make Cookie Exchanges both approachable to the general public but also optimizable by banks and professional investors, it will be essential to have Indices, or groups of stocks (like Dow Jones, S&P 500) and then also have Baskets, or ad-hoc groups of cookies bundled by analysts and audience amalgamators, in order to provide the diversification of value and risk. Many Data Management Platform (DMP)/Demand-Side Platform advertising companies may end up being significant players in the basket creation process.
Certain audiences and buying behaviors could cross exchanges via cross-ETF-market arbitrage. If Europe creates an exchange and the U.S. and China, there could be cross-exchange arbitrage to stabilize the global cookie prices. A secondary benefit of this cross-exchange arbitrage is the slowing down or reversing of the so-called “splinternet.”
Cookie Exchanges — Retargeting Refunds, Automated Lookalike Audiences & Targeting, Reduced Click Costs, “Shopping Mode” and Other Reasons to Get Excited about the Future of Advertising
I’ve been a digital strategist for over 11 years (first campaign was 15 months on President Obama’s 2007–2008 digital team) and have bought millions of dollars in ads during my career. I currently manage tens of thousands in Facebook and Google ads per month with my team, and spike more during certain seasons and launches.

I love both Facebook and Google for a lot of reasons — that’s where the majority of my budget goes (with smaller amounts through Kenshoo for Bing/Yahoo mirroring, and some other one-off networks). Google’s and Facebook’s data is the foundation of online advertising strategy for most businesses and will be for some time… But it doesn’t mean we can’t do better. And it definitely doesn’t mean that we need to remain married to a market essentially comprised of two competitors.
Cookie Exchanges open up dozens of new advertising strategies and ways to monetize audiences, grow businesses, all while protecting user privacy. Here are just a few of the ways advertisers and existing market players will be able to benefit from Cookie Exchanges…
Retargeting Refunds & Ending the Self-Defeating Retargeting Monopolies
When a company drops a cookie for a user, why does that data stay siloed? Companies would be wise to look for an open market that allows automatic expansions of audiences across networks — costs would drop, new leads would be easier to find, and walled gardens would stop artificially increasing prices for highly-targeted ads. This also promotes competition by enhancing access to the data market.
Finding more active buyers through pseudo-cookie transparency
When a visitor on your website puts an item in their cart and then does not purchase, that visitor is much more valuable on an advertising network than your average website visitor. Marketers called these opportunities, “Abandoned Carts” and they include people who are in the final stages of buying decisions, and thus more valuable to a business.
Advertising networks are making huge profits off companies that don’t realize that Abandoned Cart Retargeting ads use 100% of that companies data for the ad targeting. Retargeting ads are normally very cost-effective for marketers when compared to other ads, but the data that the company is providing the advertising firm is massively more valuable than the discount they receive on the ads.
It’s essential for publishers and product owners to take back the data they have about the intent of buyers, and start to monetize their abandon cart visitors, and the exclusion data for people who make purchases (aka they are no longer in the market for X product category).
In the Cookie Exchange, an Abandoned Cart visitor who did not complete their purchase has a high intent to potentially click on an ad of a competitor (or the original product owner) and complete a purchase. Therefore that grouping of individuals (baskets of cookies) has a higher value on the advertising open market exchange due to their increased likelihood of engaging with an ad that matches their user data. If someone in the ETF Market is betting on the futures of that basket of retargeting cookies to have consistent value stacked against other cookie properties, that would likely be a good investment.
My data, my people — the retargeting strategy fallacy
Imagine this classic retargeting scenario — currently, when you visit a website for a bicycle company and go through the process to shop for that bicycle and then almost complete a purchase, you will only start seeing ads from that bicycle company — “they own the retargeting data.”

The current retargeting strategy results in users being “followed around the internet,” which used to be a novel marketing strategy and has since backfired on the entire advertising market as users revolted to the obnoxious and repetitive experience.
Imagine again for a minute a different retargeting environment — if you visited that same bicycle website and added a bike to your cart but then didn’t purchase. In the new Cookie Exchange, your pseudo-cookie would show a high-intent to get a new bike, and every company selling bikes would be able to target ads to you with their best bike deals — a user wouldn’t just see one company, they would see real competition among businesses for their sale. This increase in ad competition would provide users a better experience, and prevent companies from burning dollar after dollar in misguided attempts to re-convert their own audiences.
This new retargeting market creates a new form of competition at the final stage of an advertising conversion and encourage competitors to compete on the open market. A company could even find a business model to provide comparisons for products, with the knowledge that accurate information reviewed by audiences prior to a purchase could still reward that publisher after any final click-advertisements prior to purchase.
Automated Audience Expansions without Facebook/Google’s “Lookalike” Audience Fees

Advertisers need to expand their audiences, and they need to stop trying to target their campaigns themselves. There are huge benefits to not targeting your advertising campaigns yourself — and to end the retargeting monopoly so that businesses can start to get retargeting ad refunds when they provide the audience data for a retargeting campaign.
Another example scenario:
User X wants to buy a BMW — goes on their website and shops around.
User X gets to the BMW checkout but doesn’t buy a car online — she stops and doesn’t give an email either.
Does that user belong to BMW?
Do users get any actual benefits when ads “follow them around the internet?”
When retargeting first came into the mix, people thought it was magic — and it worked really well to drive huge revenue. Everyone was doing it. But the strategy is saturated and the world-at-large hates the way retargeting ads follow you, and as soon as you mention a brand you start to see those brands ads. That’s due to how pixels and data are shared right now — there isn’t an actual public auction. When you say, “I may want to buy a mid-size luxury vehicle” but only visit the BMW website, you actually aren’t telling Mercedes or Aston Martin or Tesla that you’re shopping for a car. So all those car companies, that may have a car that the consumer loves, and they may have an amazing advertising campaign going on… but that user will never see those ads because they only see the BMW retargeting ads. Their shopping intent wasn’t shared in a pseudonymized way for all car companies to know and try to get their business.
The reality is that there is no individual or organization who can efficiently optimize targeting manually — it’s all hacks and tricks — and there is always a smaller segment or a missing segment that could be applied to a campaign — always. Show me someone who thinks they can optimize targeting for an ad campaign better than an ETF Market and thousands of professional optimization experts writing targeting rules and algorithms, and I’ll show you someone who doesn’t understand the power of AI and how advertising is changing.
The New “Shopping Mode”

Small business and large businesses are hemorrhaging opportunities and missing out on people who actively want to be shown more options. Why can’t a user just add one note to their pseudo-cookie “Shopping for a car between $40k-$60k” and start to see dozens of ads from car companies trying to get their business? Why does a user not have full control over when they want only 1 company to send them ads, and when they want all companies to not know their name, but to try and get their business?
Audience targeting must eventually be automated, and advertising bidding must be done in a public way to drive down costs for businesses. The closed-door advertising arbitrage at Facebook and Google and all the other major companies must end. Public ETF Cookie Exchanges tied to Shapley Value Markets to reward publishers is the only way to fix the current market imbalance while protecting user privacy.
Conclusion — Who will build the first Cookie Exchange?
GDPR has created a forced market shift by effectively stripping PII data of its value. In it’s stead, pseudonymized data will emerge as the new format to trade data beyond its original use. The value of that data and the market for it can and should be evaluated through a variation of the Shapley Value formula, whereby different “players” contribute, in-cooperation, unequally, but whereby that cooperation ensures the same or more gains as if the player acted alone.
Pseudonymized data can be traded through ETF markets of pseudo-cookies, which help to stabilize costs and promote competition of online ads.
Arbitrage of those ETFs will allow for automated targeting optimization and lookalike audiences while also complying with the privacy requirements of GDPR. This, in-turn, enhances regulatory stability and inhibits advertising fraud. New value, ie. revenue, will be generated by ETF markets and paid out to content creators, audience amalgamators and publishers.
Video Summary of the Cookie Proposal
Questions that still need to be answered about Cookie Exchanges:
1.) How does Ads.Txt play in the Cookie Exchange? The concept of ads.txt seems outdated and exposes competitive intelligence, but there are some benefits to transparent inventory management.
2.) How can the publishers considering their own walled gardens and unified login systems (particularly in Germany) reconcile their strategies with a pseudonymized Cookie Exchange?
3.) What’s the best way for a Cookie Exchange to facilitate pre-click bidding for Server-to-Server cached ad delivery (aka faster page load times)?
4.) The only way for the ETF Market and Shapley Value Formula to cooperatively exist is for the ETF Market to pay fees that are distributed to participants. What fee structures would provide $1 billion in new investments distributed through Shapley over 2 years at current data rates and expected ETF trade rates? What other rate factors should be considered?
5.) Currently the Shapley Value Formula proposed in the example Cookie Exchange had 65% of the click payout going to the network that hosted the ad (Google, Facebook, etc.) and then 35% being paid out through the Shapley Value formula to all the organizations that participated in creating data that matched the ad targeting. If the Cookie Exchange also includes an advertising/publishing DSP and hosts ads, 100% of the click value could be split with the Shapley Value Formula and the last click would just be rewarded a larger share. It’s my opinion that this current proposed 35% audience sharing rate should be artificially large at the outset of the exchange to provide a runway for audience amalgamators and current market players to continue to monetize their current assets while pivoting into the new market. I believe there could be a benefit to graduated rates that slowly reduce the 35% audience rate until the market would stabilize, and capping audience/publisher/content fees to about 25% of 3rd party ad revenue seems consistent with the impact of that audience data. The breakdown of the SVF and the significance of a “cookie contribution” needs more debate! 🙂
6.) What types of insider trading rules need to be established? How can automated rules help to find bad actors in the current market?
7.) Automated javascript pixel deployment (and SDK) error-checks are infinitely easier with a consistent advertising market like the Cookie Exchange. What types of businesses need to be developed to provide regulatory and compliance support for accurately and trusted cookie deployments? A good analogy would be meter-readers and other industries that have processes to always ensure they are accurately recording data.
8.) How could the Cookie Exchange facilitate a new type of “knowledge-based advertising” that would reward news organizations?
9.) How could the Cookie Exchange help to reclassify certain types of data as more valuable than they currently are considered?
10.) Companies like SAP who already have pseudo-cookie deployments seem to be ahead of the curve for operational challenges. What other industry organizations need to be contacted for feedback on the Exchange to ensure that work isn’t being duplicated?
11.) Facebook has over 1,300 user properties used for advertising targeting. How will the Cookie Exchange define quality data, and what caps on the number of properties per cookie session will be established, and how will the user property targeting schema be standardized?
12.) How could the Shapley Value provide data for a new search engines?
13.) Purchase exclusion audiences are infinitely more valuable than an inclusion audience and could be dominated by Amazon. How can this audience be properly valued to ensure that more companies have an incentive to improve the quality of their post-purchase data?
14.) There’s nothing stopping users who share data from also being paid via the Shapley Value formula — this is particularly true for “Shopping Mode” where a user inputs what they want and then gets bombarded with aligned ads trying to get their businesses. All Cookie Exchanges will need to determine if user payouts or dividends are essential to global market participation and more consideration for user-desires should always be a goal.
15.) What growth decay formulas will be best suited to predict cookie expirations in the ETF market?
Got other feedback or a fun project? Hit me up on Twitter @thezedwards on Linkedin or via my company website @ VictoryMedium.com if doing cool work✌

Recent Comments