Data.World intends to organize all of the world’s data, but they still need to deploy distributed organizing strategies.

The goal of Data.World has broadly been described as attempting to house all of the data for the entire world. It’s a great vision and something that needs to exist.
If they’re going to be successful organizing and updating massive amounts of data, they will need tens of thousands of volunteers helping with the mission. There are plenty of online organizations that are ideal models — from Wikipedia, Github, Sub-Reddits, and in various forums and communities across the internet. Political organizing has relied on distributed online volunteers for nearly 15 years.
Data.World is wonderful conceptually — it’s a data repository in the way that Github is a repository for code. It’s fundamentally an important community for the internet and should exist in perpetuity.
And it’s clear that Data.World is not going to immediately build their own visualization tools or internal apps (a good thing!) — it’s not going to sprawl out into dozens of complex features when the core business is focused on a very high-level goal — to organize and centralize all of the data in the world.
You can see the focus on 3rd party integrations with the current offers — they have quickly integrated with Tableau and CKAN, and are working on integrations with KNIME, Zenodo, and Algorithmia. That final integration — Algorithmia — which is the definitive marketplace for micro-algorithms — makes it clear that Data.World is not going to get into the interface business, or the app & algorithm building business. It’s another sign they are focused on their core goal.
Data.World can still improve in many ways how they teach and encourage people to build apps with their data, but the goal of Data.World isn’t to compete with Algorithmia or other systems that help you build apps & run algorithms on top of data, their goal is to organize data.
Data.World needs to help people organize data.
Companies horde their best data. Governments oftentimes provide really shitty data. And researchers sometimes don’t collect enough data, or the data points that reveal the most actionable insights. In every major big data project, part of the process is to determine what data you don’t have — and where the holes are in data. What data can be appended to a data set to make it more valuable — what’s the dream scenario if you could have any new field to filter and make that data more insightful? Who can help to flag these insights and appending opportunities?
The core concept of Github is to slowly improve code over time — just like Wikipedia slowing improving articles over time — what makes them unique and valuable is how they literally improve over time. Databases are different — they actually get stale over time. For some projects and apps, you actually need always up-to-date data, otherwise your data project turns into a history book.
Data.World is Github without pull requests, and no efforts to merge code. Data.World is Wikipedia without moderators — a confusing and untrusted resource. The splintering of efforts has a sprawling effect on quality, and only gets worse over time.
Organizing Data Starts at the Upload
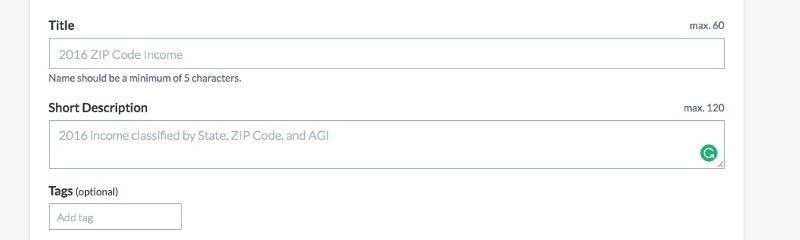
Naming conventions matter — For a company in the database business, there’s absolutely no naming conventions or best practices being applied in the creation of the current datasets and project names. Where is the “Naming Convention Team” that gets community credit for renaming open data? Where is the bot flagging that for users? Where is the brief note on the upload page? When someone creates a new dataset, there are three fields to fill out (Title, Short Description, Tags), and unfortunately, there isn’t a last-collected date field, and there isn’t a date-range-collected field, and there isn’t a location field. Furthermore, there’s no attempt to have people reuse tags, strategically add to existing topics, or use consistent language so that the world’s databases get more organized over time.
User Tags Need to be Organized by a “Tag Team” — I’ve never seen a better example of why you shouldn’t always let users create your taxonomy than what’s going on with the user tags. People have just typed random words for tags, whatever they think of, some misspellings, and the entire ecosystem is missing key words like “Maine” and other states, even though there is data for those states, just not in a searchable field. Right now, tags are not any sort of universal classification system — it’s a misleading way to browse your data and it will continue to get worse over time. Giving users control over your taxonomy and browsing structure is a recipe for a messy, inconsistent experience. If you are going to do that, you need to empower and reward other team members to be a “Tag Team” to cleanup and suggest new “verified” tags.
Time-Based Data — how often is the data being updated? When was it last updated? Every database should be “incomplete” until it’s clarified how this data gets collected in the future.
Accuracy of the Data & Stale Data — there are hundreds of “land mine” data sets on Data.World because they are out of date. They are worthless. Take this Bike Location database from San Francisco. In the text summary, it says the data was, “Created Apr 28, 2016 and last updated June 04, 2016” but another note on the page says it was updated on September 19, 2016. A link on the database page takes someone to the source government database, which says prominently that their data was updated as of July 1, 2017.
So the “Bike Location Database from San Francisco” is actually just a snapshot of that database from Spring-Summer 2016. Cooooool. What value does this database have when it isn’t up-to-date? It goes from being a living asset to a museum piece.

Out of date databases are deal breaker for businesses and app developers. If it was a “Historical Bike Location Database for San Francisco” or some other silly title, that would be fine — but it’s not — this is framed as the Bike Location Database for San Francisco.

While there isn’t some silver bullet to build an empowered and accountable community working on shared goals, there are plenty of strategies to model from existing communities. Here’s a few ideas for features and strategies †hat are modeled after Github, Reddit, Wikipedia and distributed organizing efforts:
Dataset Quality Score — The vast majority of datasets uploaded into Data.World are limited to only a “Small window of time, location or topic” — and they could be theoretically expanded. There needs to be a numeric ranking system to determine the quality of the datasets — or some classification system — it could include ranking factors like: 1.) Is the data up to date? 2.) “Been up-to-date for X months” — aka the “Syncs Per Month” stat 3.) The geographic location and how much larger and more complete the data could be with more global locations 4.) Where did the data come from? Is this a government feed that can be trusted? Is it some random spreadsheet? Is it from an “approved source?” This should likely be a 0–100 score and is very important when trying to determine whether you should use a dataset for a project or business app. This score can also be used by community members, aka “Data Wranglers,” who are trying to improve and update existing data sets.
Data.World Certified Data for Apps — There needs to be certain databases that ya’ll can determine are ~99% accurate and that will be updated regularly, and feature those for people trying to come up with ideas for new apps. It’s extremely costly and dangerous for a company to take some random data set and try to build a useful app or company out of it, without knowing what it takes to collect that data. Ya’ll can start to form more relationships with app developers by being a trusted source for accurate up-to-date databases.
Creating a new “Commit Request to Dataset Group” Feature & KPI — As you start to group your current datasets by location, time, and topic, you’ll need to clean up how other users named their data sets and help to re-organize all of the datasets. This will be an ongoing process — as the site grows, new data will continue to come, and more re-organizing will need to take place. The work never stops, until the robots take over. The long-term value in organizing every data set is immense, and the longer you wait to re-organize, the harder it will be to reimagine and rebuild this metadata infrastructure.
Creating a new “Data Hunt” Feature & KPI — As you start to group your current datasets by location, time, and topic, you’ll start to see “missing years” or “missing locations” — where maybe you have crime data on 46 states and only for 3 recent years — suddenly a task and a “Data Hunt” could come from this missing data — Data.World needs to incentivize a group of users to search out data — someone who is more like a Wikipedia editor or Sub-Reddit moderator — someone who takes ownership over keeping a topic or community updated. These editors improve quality of the data and become an extremely important part of the overall community. Genealogists have done this type of work for years, helping to build out family tree’s by finding dead ends.
Marketplace for Data Appenders & Cleaners — “Earn Money Working with Data.World” — When you start to have ~99% accurate data in Data.World for certain data sets that can be trusted — that users and businesses know will be updated and accurate, more apps can be built with this data, and with new levels of trust. There are plenty of paid-plans and premium features that could come from this, and it’s the root of how all political voter files and political voter file companies operate. There are also situations where a company could have a private database on Data.World, but need someone to help to keep it up-to-date and accurate by having someone write ingestion scripts or doing some sort of manual/semi-manual process. People with certified accounts and a history of helping to clean up the Data.World data could be paid by companies to support their data cleaning and appending efforts. Who is going to paint the digital fence and what are you going to give them to do it?
What interface would make it easiest to append valuable qualitative information into your database? When looking at a data set, what qualitative data would improve the quantitative data? What data is “missing?” A popular big-data example of this classic “appending” conundrum is traffic-accident data that can only be appended with some sort of visual/photo input. When looking at the quantitative data for car accidents at a local/state/federal level, typically the data only includes alphanumeric characters — stuff like the date, car models involved, exact location, degree of damage or injuries, etc. The general state of weather is sometimes noted. The data almost never includes photos of the intersection taken during the day and night, or details about the road leading up to the intersection, or whether it was a 2-way stop, or local environmental issues (low light, snow-covered, local distractions, etc). So if you were to only take the original quantitative data about the most accident-prone intersections, without trying to append that other “local, visual” data on top of it, you wouldn’t be able to easily recommend public policy solutions for solvable scenarios. If you could prove that a low-light, 2-way stop was 10x more dangerous than a low-light 4-way, that data could be applied to save thousands of lives per year. At some point, Data.World will need to get into the business of facilitating “appending inputs” like photo uploads and fields that need human analysis in order to make them truly valuable.

From a high-level, it’s my hope that Data.World builds out some sort of system to reward volunteers, and make it easy to find work for a volunteer.
Data holes are tasks, and tasks are goals.
Everyone doesn’t need to understand every aspect of organizing all the worlds data, but it’s going to take a diverse group of volunteers, paid staff, and daily-concerted efforts to make headway. This may not be the hands-on type of volunteer work that can have a direct impact on a community, but it’s still important work.
More close to home — since I’m based in Texas (only had part of my fence go down) and have family and friends in Houston, Corpus Christi and near Victoria dealing with direct flooding damage and ongoing storms, if you’ve read this far, please consider hopping over to the Red Cross Hurricane Harvey donation form and chipping in a few dollars. Thanks ya’ll.
Recent Comments